I love the feeling of getting to understand a seemingly abstract concept in intuitive, real-world terms. It means you can comfortably and freely use it in your head to analyse and understand things and to make predictions. No formulas, no paper, no Greek letters. It’s the basis for effective analytical thinking. The best measure of whether you’ve “got it” is how easily you can explain it to someone and have them understand it to the same extent. I think I recently reached that point with understanding standard deviation, so I thought I’d share those insights with you.
Standard deviation is one of those very useful and actually rather simple mathematical concepts that most people tend to sort-of know about, but probably don’t understand to a level where they can explain why it is used and why it is calculated the way it is. This is hardly surprising, given that good explanations are rare. The Wikipedia entry, for instance, like all entries on mathematics and statistics, is absolutely impenetrable.
First of all, what is deviation? Deviation is simply the “distance” of a value from the mean of the population that it’s part of:

Now, it would be great to be able to summarise all these deviations with a single number. That’s exactly what standard deviation is for. But why don’t we simply use the average of all the deviations, ignoring their sign (the mean absolute deviation or, simply, mean deviation)? That would be quite easy to calculate. However, consider the following two variables (for simplicity, I will use data sets with a mean of zero in all my examples):

There’s obviously more variation in the second data set than in the first, but the mean deviation won’t capture this; it’s 2 for both variables. The standard deviation, however, will be higher for the second variable: 2.24. This is the crux of why standard deviation is used. In finance, it’s called volatility, which I think is a great, descriptive name: the second variable is more volatile than the first. [Update: It turns out I wasn't being accurate here. Volatility is the standard deviation of the changes between values – a simple but significant difference.] Dispersion is another good word, but unfortunately it already has a more general meaning in statistics.
Next, let’s try to understand why this works; that is, how does the calculation of standard deviation capture this extra dispersion on top of the mean deviation?
Standard deviation is calculated by squaring all the deviations, taking the mean of those squares and finally taking the square root of that mean. It’s the root-mean-square (RMS) deviation (N below is the size of the sample):
RMS Deviation = √(Sum of Squared Deviations / N)
Intuitively, this may sound like a redundant process. (In fact, some people will tell you that this is done purely to eliminate the sign on the negative numbers, which is nonsense.) But let’s have a look at what happens. The green dots in the first graph below are the absolute deviations of the grey dots, and the blue dots in the second graph are the squared deviations:
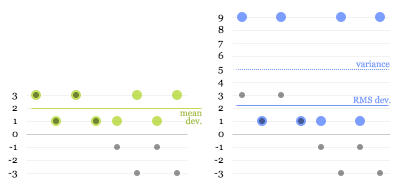
The dotted blue line at 5 is the mean of the squared deviations (this is known as the variance). The square root of that is the RMS deviation, lying just above 2. Here you can see why the calculation works: the larger values get amplified compared to the smaller ones when squared, “pulling up” the resulting root-mean-square.
That’s mostly all there’s to it, really. However, there’s one more twist to calculating standard deviation that is worth understanding.
The problem is that, usually, you don’t have data on a complete population, but only on a limited sample. For example, you may do a survey of 100 people and try to infer something about the population of a whole city. From your data, you can’t determine the true mean and the true standard deviation of the population, only the sample mean and an estimate of the standard deviation. The sample values will tend to deviate less from the sample mean than from the true mean, because the sample mean itself is derived from, and therefore “optimised” for, the sample. As a consequence, the RMS deviation of a sample tends to be smaller than the true standard deviation of the population. This means that even if you take more and more samples and average their RMS deviations, you will not eventually reach the true standard deviation.
It turns out that to get rid of this so-called bias, you need to multiply your estimate of the variance by N/(N-1). (This can be mathematically proven, but unfortunately I have not been able to find a nice, intuitive explanation for why this is the correct adjustment.)
For the final formula, this means that instead of taking a straightforward mean of the squared deviations, we sum them and divide by the sample size minus 1:
Estimated SD = √(Sum of Squared Deviations / (N - 1))
You can see how this will give you a slightly higher estimate than a straight root-mean-square, and how the larger the sample size, the less significant this adjustment becomes.
Update: Some readers have pointed out that using the square to "amplify" larger deviations seems arbitrary: why not use the cube or even higher powers? I'm looking into this, and will update this article once I've figured it out or if my explanation turns out to be incorrect. If anybody who understands this better than me can clarify, please leave a comment.
Thank you. It's one of the best explanations of standard deviation I have read.
ReplyDeleteCan you follow it up with more topics - like what is used when mean and standard deviation are the same? (skewness and ketosis). I was going through it in the last couple of months.
Also it might be interesting to explain the median in the same way and relation between mean and median.
Thanks again.
I don't understand how the second data set has more variation than the first one. The average distance to the mean is the same for both, so if you get a random piece of data then it would on average be 2 units from the mean for both data sets.
ReplyDeleteanonymous:
ReplyDeleteImagine a curve that moves up and down over time but does so smoothly, like a sine curve. Now imagine a second curve that follows the same general path but constantly fluctuates up and down as it follows the other. How do you capture that "jaggedness" of the second curve? If the fluctuation is symmetrical, the mean deviation could be almost the same for the two curves. The standard deviation, however, would be higher for the more volatile curve.
thank you so much for the interesting post! probably a stupid question, but could it be that if i have two samples A and B, that A has a higher standard deviation than B, but B has a higher mean deviation than A?
ReplyDeleteAmar, I will echo what alex said, this is probably the best i've seen so far. I'm from a control background and reqd to teach many control classes. Since the objective of control is to reduce variability, i get this question of standard d very often and especially about 'why n-1'. I think what you did was a great job... and u're right, its nice to finally understand something and be able to use it without wondering why its the way it is... thank you.
ReplyDeleteHi,
ReplyDeleteI found that your opening statement echoes word to word my feeling on understanding abstract concepts & also explaining them to others. Congratulations also on the lucid explanation. May I invite you to read this web page & comment?
http://www.leeds.ac.uk/educol/documents/00003759.htm
Amar,
ReplyDeleteI am sure you will like this...
http://betterexplained.com/articles/an-intuitive-guide-to-exponential-functions-e/
Thanks you very much, great help, i finally understand it! Jonathan
ReplyDeleteGood explanation. I would like to join in with alex uk and encourage you to write more explanations.
ReplyDeleteWoohoo! I finally figured out why that n-1 thing is there... After my exam... Good explanation by the way, very down to earth.
ReplyDeleteThank you! I have been trying to find a good visualization and no one else has done one. It would be even better animated I think. I am printing this out and taking it to my statistics class
ReplyDeletedude. ur awesome. ive been doodling on my paper trying to explain to myself why we use root-mean-square rather than standard mean. and then, i serendipitously stumbled on ur blog.
ReplyDeletegreat post, really helped me understand SD vs mean deviation
ReplyDeletethanks!
Hi Amar,
ReplyDeleteThanks for your really nice explantion of SD. It helped me a lot...
Oscar
Great explanation. Thank you. The use of 9,1,40,and 8, in particular were very helpful.
ReplyDeleteHi, I just wanted to say thanks for the clear, concise explanation. I had wondered why we take RMS also, and simply "removing the sign" wasn't the reason. I now see it as "punishing" the outliers proportionately more (3^2 = 9 vs 2^2 = 4) to show that one population is more volatile than another. Appreciate the post.
ReplyDeleteI still don't understand the need of N-1 there.
ReplyDeleteThe standard deviation is the square root of this variance, where the formula is similar to that on Wikipedia where the variance is divided by N.
ReplyDeleteIn statistics, given a set of N samples from an unknown distribution, requires the variance to be divided by N-1 (or the variance * N/N-1) so as to account for the fact that the samples are taken from an unknown distribution.
To Amar: Thank you for the concise explanation of standard deviation; it is by far one of the simplest explanations I have come across ~ very well explained. If only the authors of many math texts are capable to eloquently explain in similar manner!
It was of great help to me. In our MBA course we are made to study from lousy books which gives a rote explanation to this concept. Wish you would write a book on statistics. Thank You.
ReplyDeleteYour blog is a good attempt in explaining standard deviation. All this mathematics does not make sense to a normal user. A normal user will think how he can apply this knowledge of standard deviation. One good way of looking at it is Chebyshev's inequality.
ReplyDelete1) At least 75% of the values are within 2 standard deviations from the mean.
2)At least 89% of the values are within 3 standard deviations from the mean.
If I should be designing some thing that should work for 75% of the people, I will have to design to accommodate for all values with 2 std deviations!
http://blog.ashwins.com/2009/04/standard-deviation.html
ReplyDelete"The square root of that is the RMS deviation, lying just above 2. Here you can see why the calculation works: the larger values get amplified compared to the smaller ones when squared, “pulling up” the resulting root-mean-square."
ReplyDeleteAmplyfying a value just because it lies further away from the mean does not make too much sense to me - it just looks like we are amplyfying the more noisy samples.. in fact if you want to amplify noise then why stop at square?? why not square the square and so on..
I agree with AGB - why the square was chosen to amplify the noise is not intuitive.
ReplyDeleteTHANK YOU! I've been beating my head against the wall and now this "simple" concept is quite clear.
ReplyDeleteI appreciate this so much after hours it seemed combing the internet for an understandable definition and spend a fair amount of time staring at the wiki definition....your right its only understood by mathematical genius types which I am not!
ReplyDeleteThanks again
Wow I have been looking in stat books and on the web for about an hour and this is the best and most simple expanation i've seen. It made sense right away! Good work!
ReplyDeleteMay I please use your example in a paper I'm writing on why standard deviation is used over mean deviation?
ReplyDeleteThanks a bunch your explanations helped a lot.
Thanks for writing this
ReplyDeleteYour argument about taking outliers into account makes sense, but the question then is, why use squaring/square roots? Why not use cube/cube roots, thereby 'punishing' the outliers more? Or why not use x^1.5? The use of squares/square roots seems somewhat arbitrary, even more-so after reading
ReplyDeletehttp://www.leeds.ac.uk/educol/documents/00003759.htm
Great, great explanation. Thanks so much!
ReplyDeleteWow... How many years have I 'half' understood SD!?! I was deffo one of those people that thought the sq and sq-root was to get rid of the sign. Thank you... I only wish you'd written this 20 years ago!
ReplyDeleteI've noticed that Amar doesn't maintain this blog anymore, but nonetheless, I would like to clarify that the standard deviation in fact does not make any sense. If you were trying to figure out the average of the deviation of the data points, you would find their mean. That this doesn't show the variation between the data points is a given when you test the mean, whether the mean deviation or the ordinary mean. If that was what we were looking for, why isn't there a "standard measure of center" to replace the mean, median, and mode, which follows the formula of the standard deviation? Because it doesn't make any sense.
ReplyDeleteSo, in summary, this: "Now, it would be great to be able to summarise all these deviations with a single number" is wrong. To get an idea of the central tendency of data, we need three numbers--the mean, the median, and the mode. This is true with deviation as well. The logical thing to do is calculate the mean, median, and mode absolute deviations. Standard deviation is a convention, and I think the argument ends there.
disclosure: I don't do math or statistics for a living. (even if) show me how I am wrong if I am wrong.
Thank-you so much for the simplicity in your explanation. I wish that I could have had you as an instructor in my college statistic course. Please continue with the great work!
ReplyDeleteWow, I almost understood that!
ReplyDeleteI shall let my brain digest it for a few months and then think about it again and, hopefully, it will sink in.
Thanks for your explanation.
ReplyDeleteI still do not understand, why we use the squared values instead of e.g. abs(v^3). The only argument I can see is 'convenience' (no need for abs() with ^2), which is not really satisfying.
I also do not get the "N-1" thing.
I agree, "convenience" seems to be the explanation. Since we are talking about pre-computer's era. Square root is easy to perform "by hand". The higher the exponents the harder to do.
ReplyDeleteIn the other hand, if you use higer exponents the deviation will be numerically equal to the higest absolute diference found in data. This is true when you use ∞ as your exponent.
Thanks for the refresher course, it's been years since that was important to me. I haven't used it since I graduated.
ReplyDeleteThe closest I've come to statistics since then was charting the difference from this week's results to a 13 week median value.
Originally my manager complained about the mainframe going down and not being notified about it. This worked great. An unintended benefit was that it became a trending analysis tool. (More or fewer people were on that mainframe this week from earlier results.)
This is really a great explanation. Thanks for it.
ReplyDelete@anonymous 28 July 2010. Thanks for the link! To summarize for those that didn't click it or want to read that much: standard deviation and mean deviation are both stable indicators of variability in a sample set. Mean variation is actually better than standard deviation in real life data since it is less likely to magnify error values. However, the main advantage of mean variation is that it has a clear, intuitive meaning. As others have pointed out, you could use cubes and cube roots and it would work too, but what would the number mean?
ReplyDeleteThanks to Amar for getting me started, thanks to anonymous for finishing the job.
Thanks. Very well explained!
ReplyDeleteAccording the central limit theorem, for large enough N (in practice almost for any N) the deviations will be distributed around the mean value according to the normal law. The latter can be fully characterized by the mean value and the standard deviation calculated with the formula containing the squares. That's why the definition using the squares is so special.
ReplyDeleteGood one. thanks
ReplyDeleteFor a good discussion of the mean deviation and why it is superior to standard deviation in dealing with real world data, check out Stephen Gorard's paper here:
ReplyDeletehttp://www.leeds.ac.uk/educol/documents/00003759.htm
Key points are that
- The standard deviation is only reliable when data is normally distributed, if it is not (and it usually isn't) mean deviation is superior.
- Standard deviation amplifies errors, which Amar implied was a good thing for some reason, but in reality this means that outlying data has a disproportionate effect on the result. Mean deviation is much less affected by the odd wacky data point.
- Mean deviation is much easier to understand & could help far more people to actually understand and use statistics.
Thank you so much for writing this!
ReplyDeleteIs there any chance you'll post more such explanations of mathematical concepts?
Truly amazing! You're explained a concept that baffles so many, so concisely and clearly! I cannot thank you enough.
ReplyDeleteApprox 4.5 years after you originally posted this and it is still providing value. Thank you very much.
ReplyDeleteThe article is indeed valuable, still the whole point of SD remains unclear to me.
ReplyDelete1. What type of real-world observation demands that "jaggedness" of the sine wave(Amar's reply 16 September, 2007 22:48) to be discriminated.
2. Why would we still measure this "jagged" behaviour by the same variable (dubbing Anonymous's post 28 December, 2010 12:52).
Isn't it better to use something like
(sum of |Xi+1 - Xi|) divided by (n-1)?
gr8 post man.. its really intuitive. please post ideas about other theories n concepts as well.. you are doing a great job.
ReplyDeleteNaveen
Assuming a relatively "more" jagged distribution, doesn't the idea fall apart? In the second diagram, you have chosen all points falling on 1 or 3. Imagine that you replace the value 3 by 2.1 and 1 by 1.88. So 4 points on 2.1 and 4 points on 1.88 as against 8 points with dev 2.
ReplyDeleteAs per your theory/reasoning, we should expect the less jagged eight-2's curve to have lesser std dev than the other jagged one with values at 2.1 and 1.88. However it is just the reverse (the std dev calculated to 1.99 for the jagged curve). Note that mean again is 0. That I believe is the fallacy in your argument. You have chosen an example that supports the theory and used it as 'proof' , however that doesn't hold. Please point out if I am wrong.
P.S. I stumbled upon this blog in search of the same explanation (why std dev than mean dev?) but I cannot accept your explanation.
Thanks for the explanation. It is great post.
ReplyDeletesomething i don't understand, if we want to amplify error then why don't we sum deviations raised to the power 4 then take the fourth root? or even absolute of power 3 then third root
ReplyDeletealso, we can get 2 different graphs that have the same standard deviation but different mean absolute deviation
ReplyDeleteA concise and easy to use explanation. Many thanks from a frustrated student, who is sitting in his flat despite the beautiful weather, trying to grapple statistics...
ReplyDeleteKickass man! Good job
ReplyDelete@SAS: Perhaps I'm misunderstanding, but I don't get the result you're getting with your example. For {-2.1, -2.1, -1.88, -1.88, 1.88, 1.88, 2.1, 2.1}, I get a mean absolute deviation of 1.990 and an RMS deviation of 1.993.
ReplyDeleteAnyway, I'm looking into the concerns people have raised about using the squares, and will add an explanation/correction to the article once I've understood this.
Thanks
@SAS: Ah, I think I understand what you're saying now. Yes, the numbers you suggested have more variability than 2s and -2s, but they're also closer to the mean on average (1.99 vs 2.00). I chose 1s and 3s because they have the same mean deviation as the 2s, and I wanted to isolate the effect of measuring variability.
ReplyDeleteAwesome explanation. Taking a basic stats class at UC Irvine and this just made it click!
ReplyDeleteTwo comments:
ReplyDeleteRegarding the use of higher powers to "amplify the tails," so to speak: this is known but is not commonly used. By using the third power, you will get a measure of how skewed the data is. Roughly speaking this would be a measure of the spread between mean and median.
Using the fourth power is a measure called kurtosis. This measure is roughly intended to give some idea of how heavy the tails are (or how many data points are a distance away from the mean).
Regarding the intuition of the bias of the estimated standard deviation the simple answer is that the average used to calculate the standard deviation has an error in it. When you account for the effect of this error on the estimated standard deviation, you get the N-1 term.
More technically, what is happening is this: if the assumption is that all the data points are drawn (with replacement to make is simple) from a distribution with a mean and a variance then the assumption is that the drawn value of each data point can be of any of the potential values of the sample space of distribution. This is absolutely true for for the first N-1 draws for a sample of size N. However, this is not true for the Nth draw because the Nth draw is constrained to a sample space of the single value that sets the final average that was used as the estimated mean to calculate the sample standard deviation. This means that the data point is drawn from a different sample space.
Therefore, since 1) the standard deviation really is just an average of the square of the difference between the data points and the estimated mean; and, 2) to be meaningful, the data points should be drawn independently from the same sample space then it is appropriate to adjust the calculation not counting the last, constrained data point.
Note that when you have access to the entire population this problem goes away, which is why there is the difference between population variance and sample variance.
I know this is a lousy explaniation but it is the best I got.
Sorry
Thanks for the explanation. Not fully there, but somewhat understood : )
DeleteFor days, I have been trying to figure out exactly why the difference was to be squared, and your example nails it! As to squaring or cubing or higher levels, I believe that it would amplify the results even more. Squaring should be sufficient for intuition for statisticians, I think. I will however try to extend your example using cubes and see how it works out. But thank you so much for this really beautifully explained article!
ReplyDeleteThanks Amar!
ReplyDeleteThank you for saving my sanity. This is an amazing explanation.
ReplyDeleteThe higher powers can be used to define moments of distribution. Skew, Kurtosis etc.
ReplyDeleteFrom stats exchange: ‘the standard deviation is a term that arises out of independent random variables being summed together. So, I disagree with some of the answers given here - standard deviation isn't just an alternative to mean deviation which "happens to be more convenient for later calculations". Standard deviation is the right way to model dispersion for normally distributed phenomena.’
ReplyDelete"Model dispersion for normally distributed phenomena" this is exactly the type of jargon amar tried to avoid.
Deletearticle was written in 2007 , and its 2023 now and still this is the best explanation I found on the web. thanks a lot Amar
ReplyDeleteAmazing Explanation, Thanks
ReplyDelete